헬스케어 챗봇의 현재와 가까운 미래 - 들어가며

1 .시작하며
안녕하세요 @doctorbme 입니다. 이번에는 헬스케어 챗봇(chatbot)과 관련된 글을 적어보려 합니다. 챗봇하면 정말로 우리에게 말을 걸어주고 응답하는 인공지능 비서같은 서비스를 떠올리기 쉽습니다. 하지만 혹시 예전 MSN 메신저를 쓰던 세대라면 심심이 같은 서비스를 떠올리실 수도 있을 겁니다. 아니, 챗봇의 목적이 사용자와 대화하거나 사용자의 의도를 파악하여 적절한 응답을 출력한다는 것을 상기해본다면 우리가 흔히 쓰는 ARS 나 상담원의 서비스도 아주 넓은 의미의 챗봇이라고 여길 수도 있겠습니다. 왜냐하면 결국 주어진 매뉴얼과 로직에 따라서 사용자의 입력에 대해 반응하고 행동하게 되는 것이니까요.
하지만 그게 무슨 챗봇이냐고 생각하실 분도 있으리라 봅니다. 챗봇이라 하면 모름지기 구글 어시스턴트나 애플의 시리 정도는 되어야 하지 않나 싶은 마음도 드니까요. 내가 말하는 대로 정확히 인식해서 실행하고 반응하는 것, 우리는 이정도는 되어야 챗봇으로서 역할을 잘 수행하고 있다고 느낄 수도 있습니다. 튜링 테스트의 서비스 버전이라고 할까요.
2 . 규칙 기반의 응답과 자연어처리
아까 말씀드렸듯이 아주 넓은 의미의 챗봇은 ARS나 질문을 선택하는 형태의 서비스를 포함한다고 생각합니다. 다만 지시나 응답에 관한 자유도가 현저하게 낮을 뿐이지요. 어떤 질문에 A라는 답을 했다면 2번 질문으로 가고 B라는 대답을 했다면 3번 질문으로 가는 구조를 만들어볼 수 있습니다. 하지만 우리는 좀 더 자유롭게 표현하고 표현된 문자들이 잘 인식되기를 원합니다. 같은 내용에 대해서 살짝 다르게 표현할 수 있는 것입니다. 아니면 같은 내용으로 보인다고 할지라도 실상을 들여다보면 비슷하게 보이지만 완전히 같지는 않은 뉘앙스를 가지고 있을 수도 있습니다. 그래서 자연어 처리가 필요합니다.
이번 글에서 자연어 처리의 방법론을 설명하지는 않을 것입니다. 중요한 점은 챗봇 서비스에서 입력받는 형식의 자유도를 높이기 위해, 다시 말하자면 인간이 말하고 쓰는 문장을 처리하기 위해 자연어 처리가 필요하다는 것입니다. 특히나 뉴럴네트워크를 사용한 모델은 꾸준히 발달해왔고 의미있는 특성을 뽑아낼 수 있습니다. 특히 우리가 사용하는 어휘들로부터 감정을 추출할 수 있다는 것은 챗봇이 단순히 정보를 인식하고 전달하는 것을 넘어서 사용자의 감정과 기분을 반영하여 대응할 수 있다는 것을 뜻합니다.
그렇다고 하여 규칙 기반의 분류나 반응이 중요하지 않다는 것은 절대로 아닙니다. 사용자의 상태를 파악할 때 일종의 가이드라인이나 판단 기준들이 계층적으로 존재하는 경우가 많고, 사용자가 어떤 상태에서 다른 상태로 넘어갔거나 상태 자체를 세부적으로 파악하기 위해서는 결국 구조적인 규칙들이 필요합니다. 다만 서비스가 규칙 기반으로만 형성되고 사용자의 입력도 이에 기반해서만 이루어진다면, 아무래도 사용자 입장에서는 흥미가 떨어지거나 기존 서비스와 별반 차이가 없다고 느낄 가능성이 높을 것입니다.
3. Woebot의 사례
사용자의 기분과 감정을 챗봇이 파악할 수 있다면 뭔가 이를 기반으로 사용자에게 유용한 기능을 제공할 수 있지 않을까요? 이런 서비스 중 하나가 바로 Woebot 입니다. 겉으로 보기에 Woebot의 화면과 서비스는 간단합니다. 처음 실행을 시키면 사용자의 의도와 목적을 묻고, 그 다음부터는 바로 채팅창 하나만 보일 뿐입니다.
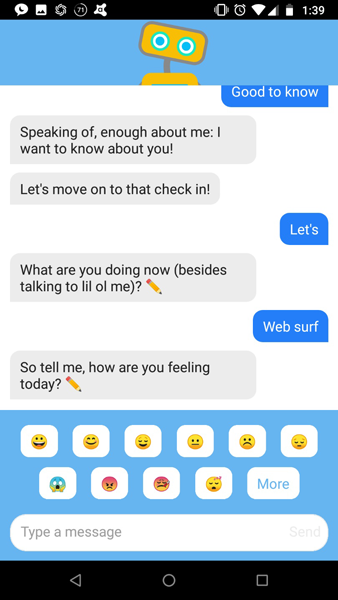
실행을 시키면 Woebot이 사용자에게 말을 겁니다. 그날의 기분을 체크하기도 하지요. 사용자의 반응에 따라서 적절히 대응을 하도록 설계되어 있습니다. 물론 꼭 필요한 정보의 경우에는 튜토리얼처럼 전달하기도 합니다.
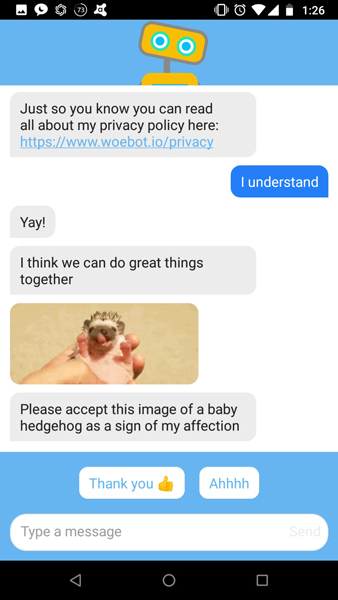
헬스케어 챗봇이 그냥 챗봇과 다른점이 하나 있다면, 사용자가 스스로 위급하거나 위험하다고 느끼는 경우 챗봇이 개입을 할 수 있도록 하는 기능을 생각해 두고 있다는 점입니다.
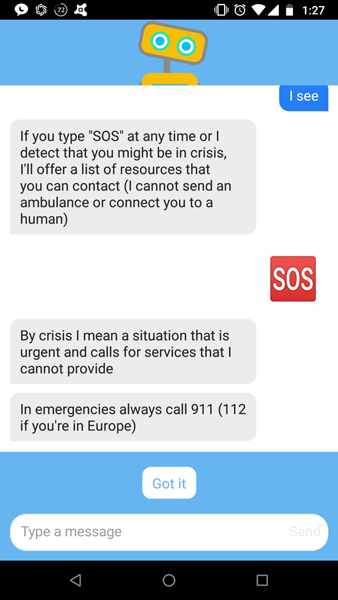
Woebot의 경우에는 인지행동치료를 위한 챗봇인데다가, 심각한 사용자가 활용하기보다는 정상적이거나 경미한 정도의 우울감을 가지고 있는 학생들을 대상으로 해서 그런지 직접 개입하기보다는 도움을 받을 수 있는 경로를 제시해주는 선에서 그치고 있기는 합니다. 아마 가짜 구조 요청이나 구조 요청의 남발을 방지하기 위한 장치가 아닌가 싶습니다. 만약 사용자의 상태에 관한 진실성 체크가 충분한 수준으로 이루어진다면, 개입의 수준도 더 다양해지고 깊어지지 않을까 예상합니다.
사실 Woebot은 대화형 챗봇이 인지행동치료를 함에 있어서 얼마나 도움이 될 것인가에 대한 연구를 위해 사용되기도 하였습니다. 스스로 생각하기에 불안감이나 우울감을 가지고 있는 대학생들을 대상으로, 자가 학습을 통해 자신의 기분을 개선시킬 수 있는 형태로써 대화형 챗봇과 eBook 중에 어떤 것을 선호하고 효과가 어떨지를 판단하는 연구였습니다.
우울증에 관해 스크리닝 및 심각도를 1차 의료 현장에서 간단하게 평가할 수 있는 PHQ-9 점수의 변화 양상을 살펴보면, 확실히 대화형 챗봇의 형태가 좀 더 좋은 결과를 보여줍니다.
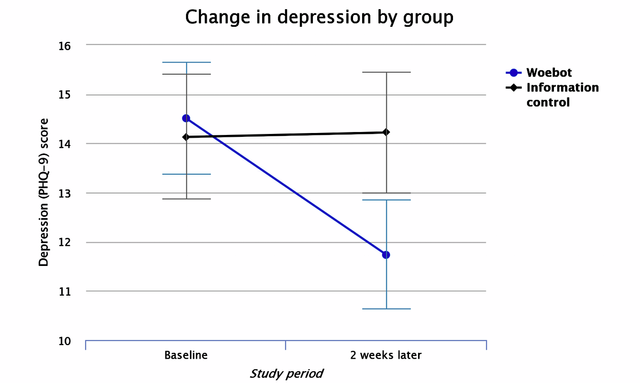
출처: Fitzpatrick KK, Darcy A, Vierhile M, Delivering Cognitive Behavior Therapy to Young Adults With Symptoms of Depression and Anxiety Using a Fully Automated Conversational Agent (Woebot): A Randomized Controlled Trial, JMIR Ment Health 2017;4(2):e19
저작권: Creative Commons Attribution License - CC BY 4.0
하지만 이런 형태의 챗봇에서 단점이 지적되기도 했는데요,
- 자동화된 반응이 대화의 맥락이 맞지 않았다.
- 대화가 반복되는 양상을 보였다.
- Woebot에서 제시되는 버튼 (사용자가 직접 입력할수도 있지만, 추천 응답을 선택할 수도 있습니다.)을 입력했을 때 적절한 반응을 보기 힘들었다.
- 추천 응답, 특히 이모티콘이 별로였다.
- 대화가 너무 짧았다
- 제시된 어떤 비디오는 너무 길었다
위와 같은 부정적 피드백이 보고되기도 했습니다. 이 중 중요한 것은 대화의 맥락에 맞지 않거나 챗봇이 적절한 반응을 하지 못한 것일텐데, 사용자의 응답 (문장 구성) 자유도가 높은만큼, 길고 복잡한 문장이나 충분한 학습이 이루어지기 어려운 (예외처리 수준의) 응답이 아니었나 짐작해봅니다. 사실 이런 문제는 일반적인 챗봇이나 음성 인식 서비스에서도 종종 발생하는 케이스이기도 합니다.
4. 마무리
저는 챗봇이 상당히 다양한 분야에서 사용될 것으로 전망하고 있습니다. 하지만 광범위한 목적이 일반적인 챗봇에 대해서는 챗봇이 학습해야할 지식도 방대하고 특정 맥락을 파악하기 위한 어려움이 많습니다. (이것이 이루어진다면 정말로 완벽한 챗봇이 되겠지요.) 따라서 각 분야마다 전문적인 지식과 일반적인 표현이 결합된 문장들에 대한, 특화된 자연어처리가 필요할 것으로 생각합니다. (일반적인 지식과 일반적인 표현이 결합된 문장들을 통해 일상의 불편함을 간단하게 해소하는 서비스는, 이미 애플이나 구글, 우리나라의 대기업 등을 통해 보급되고 있으니까요.)
헬스케어 챗봇의 경우에는 사람의 건강과 직결되는 분야를 다루기 때문에 실제로 챗봇이 안전한지, 효과가 있는지를 판단하는 것이 다른 분야의 챗봇과 다르게 상당히 중요한 문제로 떠오를 것입니다. 그래서 임상시험의 형태로도 연구를 진행하게 됩니다. 복잡하고 다양한 기능을 구현할수록 검증의 시간과 자원이 더 많이 필요할지도 모릅니다. 우리의 건강을 관리하는 것부터 진료와 치료에 도움을 주고 환자의 상태를 개선하는 것까지 다양한 계층의 목적이 존재할 수 있습니다. 그리고 간단히 클릭하는 형태부터 우리의 음성을 인식하고 뜻을 파악하는 것까지 입력의 복잡성이 달라질 수 있습니다. 이 수준을 어떻게 결정해야하는 걸까요. 과연 어떤 종류의 헬스케어 챗봇들이 등장할 수 있을까요.

자연어 처리가 가장 힘들죠.
특히 한국어는 노란, 노랑, 노랭이, 누런, 누리끼리 ......
A질문에 대한 B대답이라는 원리는 단순한데 A질문이라는 의미를 해독하는게 가장 힘든 것 같아요.
그런면에서 구글 AI은 한국어 해독이 참 대단 한 것 같아요.
단순히 A냐 A가 아닐 것이냐 정도의 binary classification 정도라면 어렵지 않겠지만, 질문이 가질 수 있는 많은 의미를 파악하는게 참 어려운 것 같습니다. 번역 정도라면 RNN 같은 걸 써서 완벽하게 의미파악을 하지 못하더라도 출력하게 하면 그만일 수도 있는데, 전문적 지식 영역이 결합된 처리는 일반적 의미와 분야적 지식의 쓰임을 구분해야할 경우도 생기기 때문에 더 어렵게 느껴지네요.
구글처럼 사용자가 많고 데이터가 많이 쌓인다면 + 연구가 활발히 이루어지는 조직을 가지고 있다면 아무래도 접근하기 좀 더 용이하지 않을까 싶습니다.
Congratulations @doctorbme! You have completed the following achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOP