How Search Engine works
Search engine လို.ဆုိလုိက္ရင္ ဘာသြားေၿပးၿမင္မလဲဆုိေတာ့ Google ကုိသြားေၿပးၿမင္ၾကမွာပါ။ Google အလုပ္လုပ္ပံုကုိ အေသးစိတ္ရွင္းၿပႏုိင္ဖုိ.လဲမၿဖစ္ႏုိင္လုိ. အၾကမ္းဖ်င္းေလာက္ကိုပဲ ေရးၿပႏုိင္မွာပါ။ Search Engine ေတြကုိနားလည္ဖုိ. ဘာေတြနားလည္ဖုိ.လုိလဲဆုိရင္ Computer science က Information retrieval ဆုိတဲ့ field ရယ္ ေနာက္ AI, Machine Learning, Distributed Computing အစရိွတာေတြကို နားလည္ထားဖို.လိုပါတယ္။ Information retrieval ဆုိတာ ဘာကိုဆုိလုိတာလဲလို.ေမးလို.ရိွရင္ေတာ့ text file ေတြ flat file ေတြ structure မက်တဲ့ file ေတြထဲကေန content ေတြကို ဆြဲထုတ္တာ လုိအပ္တဲ့ information ေတြကို keyword ေတြ pharase ေတြသံုးၿပီး ရွာတာလို.ေၿပာရမွာပါပဲ။ Google တခုလံုးသည္ IR (web information retrieval) ကိုလုပ္ေနတယ္လို.ဆုိရမွာပါ။ Large scale serch engine ၿဖစ္တဲ့ Google က်ေတာ့ ဘာၿပႆ နာေတြရိွလဲဆုိေတာ့ index လုပ္ရတဲ့ document ေတြ web page ေတြ trillion ရာနဲ.ခ်ီရွိေနတာပါ။ အဲ့ေကာင္ေတြကို process လုပ္ရတဲ့ ၿပႆနာ ပိုလာပါတယ္။ ဒါေတြကုိက်ေတာ့ Distributed computing algorithm ေတြကိုသံုးၿပီး ေၿဖရွင္းပါတယ္။
Search engine လုိ.ဆုိလုိက္ရင္ အဓိက က်တဲ့အပုိင္း ၃ပိုင္း ပါပါတယ္။ အဲ့ဒါေတြက
Crawling
Indexing
Searching or Ranking
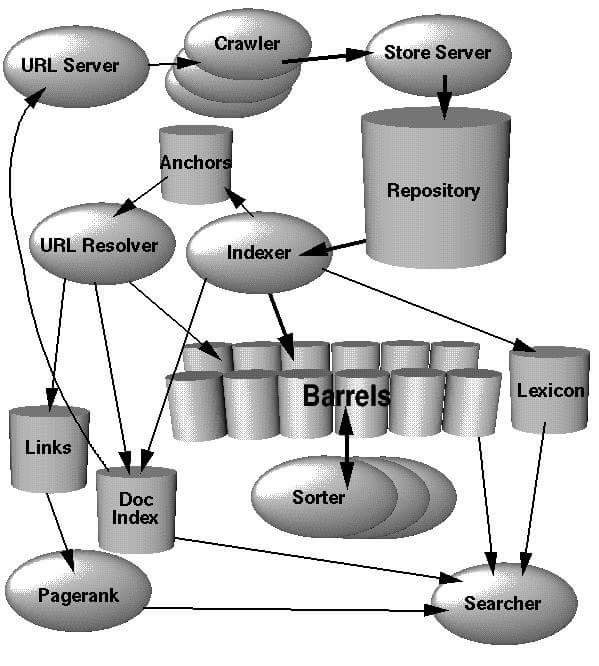
ဆုိတဲ့ သံုးခုပါ။ ေအာက္က ပံုက Sergey Brin နဲ. Lawrence Page ရဲမူလ paper ၿဖစ္တဲ့ The Anatomy of a Large-Scale Hypertextual Web Search Engine မွာၿပထားတဲ့ပံုပါ။
Crawling
ပထမဆံုး search engine ေတြဟာ user ေတြ query ေတြရိုက္မရွာခင္ သူတုိ.က internet မွာရိွတဲ့ web page ေတြ အရင္ဆံုး သူတုိ. index server ေတြမွာ သိမ္းထားဖုိ.လုိပါတယ္။ အဲ့လို internet ေပၚမွာရိွတဲ့ web page ေတြကို တရြက္ခ်င္း လိုက္ save မေနပါဘူး။ Crawler ကိုသံုးၿပီးေတာ့ internet ကုိေလ်ာက္သြားပါတယ္။ ထူးေတာ့ ထူးဆန္းေနပါလိမ့္မယ္။ Crawler သည္ internet ကုိေလ်ာက္သြားတယ္။ ေနာက္ ေတြ.တဲ့ page ေတြကို download လုပ္တယ္။ ေနာက္ index server ကိုပို.တယ္။
Crawler ကဒီလိုတဆင့္ခ်င္းလုပ္တယ္။
URL Queue ဆုိတာ သူ.ဆီမွာ ပထမဆံုး စ Crawl ရမဲ ့web site list ေတြကိုထဲ့ထားတယ္။
URL Queue ထဲကေန link တခုကို ယူလုိက္တယ္။ အဲ့ဒီလင့္ရိွေနတဲ့ web page ကုိ download လုပ္တယ္။
ေနာက္ ခုနက download လုပ္ထားတဲ့ web page ထဲမွာပါတဲ့ တၿခား နဲ.ညႊန္ထားတဲ့ page ေတြကို regular expression ေတြသံုးၿပီး ဆြဲထုတ္တယ္။ အဲ့ဒီေတာ့ page တခုသည္ တၿခား link ေတြကို ညႊန္ထားရင္ Crawler သည္ အဲ့လင့္ေတြကုိ ဆက္သြားလို.ရသြားတယ္။
အဲ့လိုနဲ. crawler သည္ မရပ္မခ်င္း internet ေပၚက page ေတြကို download လုပ္သြားတယ္။
Googleလို large scale search engine ေတြက်ေတာ့ Crawler တခုတည္းမသံုးဘူး။ Distributed Crawler ေတြသံုးတယ္။ Distribute Crawler ဆုိတာ crawler ေတြအမ်ားၾကီးကို geographically အရ ခြဲထားတာမ်ိဳး။ သူတုိ.အခ်င္းခ်င္း download လုပ္တဲ့ link ေတြ မထပ္ေအာင္ crawl လုပ္ၾကတယ္။ ေနာက္ index server ထဲကိုၿပန္သိမ္းၾကတယ္။
Indexing
Indexing ဆုိတာက ခုနက Crawler က download လုပ္လုိ.ရလာတဲ့ web page ေတြသည္ html page ေတြပဲၿဖစ္တယ္။ ဒီေကာင္ေတြကုိ ရွာဖုိ.မလြယ္ဘူး။အဲ့ေတာ့ ရွာဖုိ.လြယ္ေအာင္ webpage ေတြကို token ေလးေတြ word ေလးေတြတခုခ်င္းၿဖစ္ေအာင္ ဖြဲ.တယ္။ေနာက္ a,and,the တုိ.လို မလိုအပ္တဲ့ stopword ေတြဖယ္ၿပစ္တယ္။ ေနာက္ programming, programmer ဆုိရင္ root form ၿဖစ္တဲ့ program ၿဖစ္ေအာင္ stemming algorithm ေတြသံုးၿပီး index structure နဲ.သိမ္းတယ္။ မ်ားေသာအားၿဖင့္ေတာ့ information retrieval field ထဲက inverted index structure နဲ.သိမ္းၾကတယ္။ မ်က္စိထဲၿမင္ေအာင္ၿပရရင္ ႏုိင္ငံၿခားကထုတ္ထဲ့ စာအုပ္ေတြ ေနာက္ဆံုးမွာ index ဆုိတာပါတယ္။ သူက ဘယ္ word သည္ ဘယ္စာမ်က္ႏွာမွာ ပါတယ္ဆုိတာကို မွတ္ထားတာ။ Index ေတြရဲ.သေဘာကလဲ အဲ့လိုပဲ ဘယ္ word သည္ ဘယ္ web page URL မွာပါတယ္ဆုိတာမ်ိဳးကိုမွတ္ထားတာ။ ဒီေနရာမွာလဲ data storage သည္ တအားၾကီးတဲ့အတြက္ single individual MySQL server ေတြကို clustering လုပ္ၿပီးေတာ့ သိမ္းတယ္။
Ranking
ဒီအပိုင္းကေတာ့ အရွုပ္ဆံုးလုိ.ေၿပာရမယ္။ Google က ဘာကိုသံုးလဲဆုိေတာ့ PageRank ဆုိတဲ့ Algorithm ကိုသံုးတယ္။ PageRank က ေက်ာရိုးသေဘာပဲရိွတာ။ Ranking algorithm သည္ အၿမဲေၿပာင္းလဲေနတယ္။ အေၿခခံအားၿဖင့္ေတာ့ PageRank ကဘယ္လိုလုပ္သလဲဆုိရင္ web page ေတြမွာရိွတဲ့ link ေတြကို incoming link (တၿခား page တခုခုကေန သူ.ကိုညႊန္းထားတဲ့ link) ေနာက္ outgoing link (သူကေန တၿခား page ကိုညႊန္းထားတဲ့ link ) အစရိွတာေတြကို တြက္တယ္။ Incoming link (သူမ်ားေတြက ညႊန္တာမ်ားရင္ သူက rank တက္တယ္) လူေတြလိုေပါ့ ေက်ာ္ဟိန္းဆုိ လူတုိင္းသိတယ္။ Ranking အရဆုိရင္ ေက်ာ္ဟိန္းဆီ ၀င္လာတဲ့ link ေတြမ်ားတယ္။ ဒါေၾကာင့္ ေက်ာ္ဟိန္းသည္ rank ပိုရမယ္။ ေက်ာ္ဟိန္းက က်ေတာ့ လူေတြ အမ်ားၾကီး သိခ်င္မွသိမယ္။ ဥပမာ Java ဆုိၿပီးရွာလုိက္ရင္ Oracle ဆုိက္ကို ၀ုိင္း ညႊန္တာ မ်ားတဲ့အတြက္ Oracle ရဲ. rank သည္ ပိုတက္လာမယ္။ ဒါက အေၿခခံ တၿခားထဲ့တြက္ရတဲ့ AI, Machine learning အစရိွတာေတြသည္ Google ေနာက္ကြယ္မွာရိွဦးမွာ။ Ranking ကုိဘာလုိ.လုပ္ရသလဲဆုိေတာ့ Search result ေတြသည္ မ်ားေနေတာ့ဘယ္ေကာင္သည္ relevant အၿဖစ္ဆံုးလဲဆိုတာ တြက္ဖုိ.လိုတယ္။ အဲ့ေတာ့ user ကုိထုတ္ၿပရင္ rank အမ်ားဆံုးေကာင္ကို ထိပ္ဆံုးကေနၿပလိုက္တယ္။
Larry page တုိ. paper သြားဖတ္ခ်င္ရင္ေတာ့ အေပၚကေပးထားတဲ့ paper title နဲ.သာ google သြားရွာၾကည့္။
ေတာ္ေသးဘီ။
MSO 17
Congratulations @scamtapper! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPေရးထားတာေကာင္းပါတယ္ဖတ္ရတာလည္းမူးသြားတယ္ဆက္ႀကိဳးစားပါ ေညး . မူးဝါးေအာင္😂😂😂😂